複数の拠点や部署にデータが分散している環境では、必要な情報を集約するだけで膨大な時間を浪費してしまいます。筆者の経験では、経理の月次報告において、各部署から送られてくる売上集計ファイルを手作業で転記する作業が、担当者の精神的な負担と深夜残業の温床になっているケースを数多く見てきました。Excelでいう「ブック間の参照」をクラウド上でより柔軟に行うためのスキルを習得することは、実務のスピードを決定づける重要な要素です。
Googleスプレッドシート IMPORTRANGEで解決できるデータの「分断」
複数のスプレッドシートにまたがるデータを一つのマスターシートに統合する際、最も汎用性が高いのが「Googleスプレッドシート IMPORTRANGE」関数です。この関数は、外部のファイルから指定した範囲のデータをリアルタイムで参照し、自動更新する仕組みを持っています。
ファイル間の壁を取り払うメリット
各部署が個別のファイルで管理している「営業部_売上管理表」「総務部_備品購入リスト」「経理部_経費精算書」といったデータを、一箇所に集約できることが最大の利点です。データの所在が分散していると、最新版がどれかわからなくなる「情報の先祖返り」が発生しやすくなります。この関数を使えば、各担当者は自分のファイルを更新するだけで、管理者のマスターシートには常に最新の結果が反映されます。
Excelの外部参照との違いと優位性
Excelの場合、ネットワーク上の別ブックを参照するにはファイルパスを指定しますが、ファイル名が変わったり保存場所が移動したりするとリンク切れが多発します。一方、スプレッドシートはファイル固有のID(URLに含まれる文字列)で管理するため、ファイル名やフォルダの場所を変更してもリンクが維持されます。この安定性は、頻繁に組織変更やファイル整理が行われる実務現場において大きな強みとなります。

複数のファイルを手作業で集計するリスク
実務において「コピー&ペースト」による集計は、最も避けなければならない運用の一つです。一見すると手軽ですが、規模が大きくなるほど管理不能な状態に陥ります。
転記ミスが招く致命的な計上漏れ
経理の現場では、この設定を忘れて集計がずれるケースをよく見かけます。例えば、前月までのフォーマットに1行追加されたことに気づかず、古い範囲をコピーしてしまい、特定の社員の売上実績が丸ごと抜け落ちてしまうといったミスです。人間が介在する作業が増えるほど、エラー率は統計的に上昇します。
情報の鮮度が落ちることによる意思決定の遅れ
手動集計を行っている場合、マスターシートが更新されるのは「集計担当者が作業を終えた時」だけです。これでは、経営層が「現在の正確な在庫状況」や「リアルタイムの予算進捗」を確認したくても、数日前のデータしか見ることができません。情報の鮮度はビジネスの判断材料としての価値に直結します。
確実なデータ連携を実現するための実務ステップ
実際にデータを取得するための手順を確認します。基本構文はシンプルですが、実務ではシート名にスペースが含まれる場合の処理など、細かい配慮が求められます。
構文の基本ルール
基本となる数式は以下の通りです。
`=IMPORTRANGE(“スプレッドシートのURL”, “シート名!範囲”)`
第一引数には参照したいスプレッドシートのURL全体、またはIDを指定します。第二引数には「’売上集計’!A1:E100」のように、シート名とセル範囲を指定します。
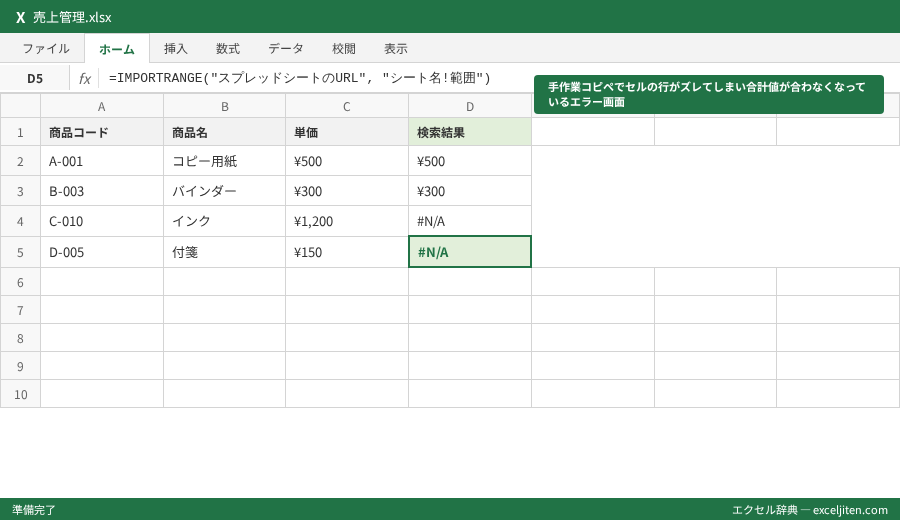
アクセス許可のプロセス
関数を最初に入力した際、必ず「#REF!」エラーが表示されます。これは、ファイル間のアクセス権限がまだ承認されていないためです。セルにマウスを合わせると表示される「アクセスを許可」という青いボタンをクリックすることで、初めてデータが表示されます。
注意点: アクセス許可は「参照先(読み取り側)」のファイルの編集権限を持つユーザーが行う必要があります。一度許可すれば、そのファイルを利用する他のユーザーもデータを閲覧できるようになります。
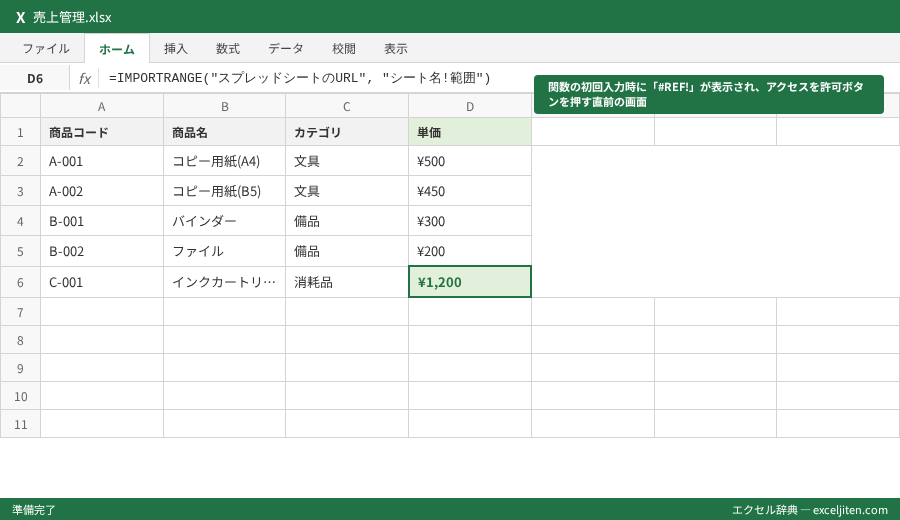
応用編:QUERY関数との組み合わせで必要なデータだけを抽出する
実務では、参照元のデータをすべて取り込むのではなく、特定の条件に合致するデータだけを抽出したい場面がほとんどです。ここで重要になるのが `QUERY` 関数との併用です。
売上実績から特定の部署データだけを抽出する例
例えば、全社の売上リストから「営業部」のデータだけを抽出したい場合、以下のように記述します。
`=QUERY(IMPORTRANGE(“URL”, “全社売上!A:Z”), “SELECT * WHERE Col2 = ‘営業部'”)`
このように組み合わせることで、不要な行を読み込むことなく、必要な情報だけが整理された状態でマスターシートに表示されます。
実務データ構成の工夫
顧客リスト(顧客ID、社名、担当者)や請求書データ(請求番号、取引先、金額、支払期日)を取り扱う際、参照元の列順が変わるリスクを考慮し、列全体(A:Zなど)を指定しておくのが定石です。これにより、データが下方向に追加されても、再設定なしで自動的に反映され続けます。
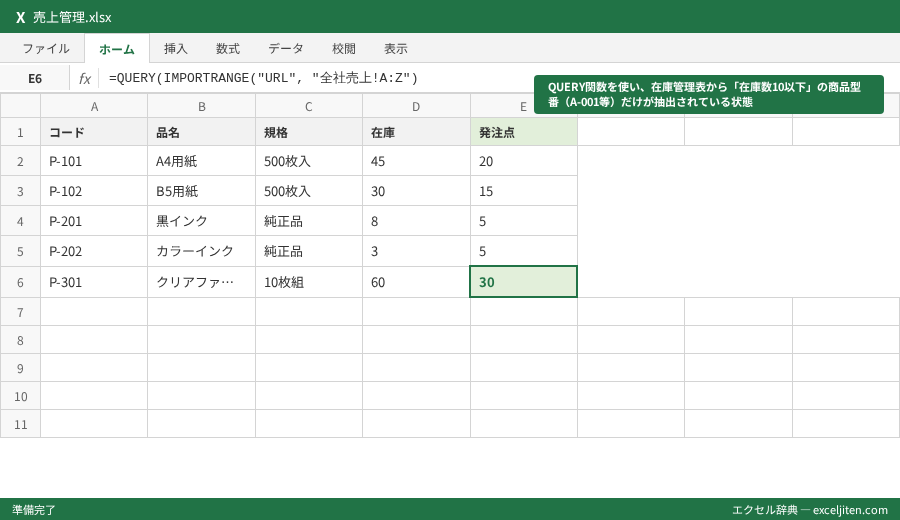
エラーが発生した時の原因特定チェックリスト
「昨日まで動いていたのに急にデータが消えた」というトラブルは、スプレッドシート運用で最も多い相談の一つです。社内研修で講師をしていると、URLの指定範囲を間違えてエラーで止まってしまう初心者が非常に多いことに気づきます。
よくあるエラーメッセージとその対策
- #REF!(アクセス権限不足): 参照元のファイルの共有設定が変わったか、アクセス許可が切れた可能性があります。
- #VALUE!(引数の形式不備): URLやシート名をダブルクォーテーション(”)で囲んでいない場合に発生します。
- #N/A(データ未検出): QUERY関数などで抽出条件に一致するデータがない場合に表示されます。
大規模データにおけるパフォーマンスの低下
参照するデータ量が数万行を超えると、計算に時間がかかり「読み込んでいます…」という表示が消えなくなることがあります。これはGoogleのサーバー負荷によるもので、一つのファイルにあまりに多くの関数を詰め込みすぎると発生します。
ポイント: データの更新頻度がそれほど高くない場合は、値を固定するなどの運用を検討してください。過度な連結はシート全体の動作を著しく重くする原因となります。
15年の実務経験から導き出した運用のコツ
長年Excelやスプレッドシートを実務で使い込んできた中で、単に関数を使えるだけでなく、「壊れにくい構造」を作ることが最も重要だと確信しています。
URLを直接入力せずセル参照を利用する
数式内に長いURLを直接書き込むと、後からの修正が非常に困難になります。管理用のシートを作成し、A1セルにURLを貼り付けておき、数式からは `IMPORTRANGE(A1, “シート名!範囲”)` と参照させる方法がスマートです。これにより、参照元のファイルが差し替わった際も、1箇所のセルを書き換えるだけで済みます。
ショートカットキーを駆使したデバッグ
データの参照が正しいか確認する際、URLをコピーして新しいタブで開く作業を繰り返します。このとき、`Ctrl + L`(アドレスバー選択)や `Ctrl + C`(コピー)のショートカットを体に染み込ませておくと、調査スピードが格段に上がります。
データの肥大化を防ぐための「フィルタリング」
実務でよく見かけるのは、参照元ファイルを削除してしまい、集計用シートが全滅するトラブルです。これを防ぐために、参照元には「削除禁止」というシート名を明示したり、バックアップ用のGAS(Google Apps Script)を組んだりする対策も有効です。また、Excelとの互換性を保つ必要がある場合は、Microsoft公式サイトで提供されている関数比較表などを参考に、代用可能な機能を確認しておくことを推奨します。
参照:
– Microsoft公式サイト:Excel と Google スプレッドシートの関数の比較
– Microsoft公式サイト:Office 開発者向けのサンプルとリソース
まとめ
業務の効率化において、ツールをどう使いこなすかは極めて重要です。以下の3点を意識して運用を組み立ててください。
- 手作業の転記を排除し、IMPORTRANGEによる自動連携を標準の仕組みにする
- QUERY関数を組み合わせ、マスターシートには「必要な情報」だけを表示させる
- エラーに強い構造にするため、URLのセル参照や列全体の指定を活用する
データの正確性が担保され、リアルタイムでの集計が可能になれば、分析や戦略立案といった本来の業務に充てる時間を創出できます。まずは小規模な在庫リストや勤怠管理の集計から、この関数の活用を試みてください。


コメント