外部システムからエクスポートした「売上実績.csv」や「顧客リスト.csv」をExcelで開いた瞬間、画面一杯に広がる意味不明な漢字や記号の羅列。経理部門や営業管理の現場で、月末の多忙な時期にこの光景に直面し、冷や汗をかいた経験を持つ方は少なくないはずだ。この現象は決してデータが破損したわけではなく、単にExcelとファイルの「言葉の解釈(文字コード)」が食い違っているだけに過ぎない。仕組みを正しく理解し、適切な手順を踏めば、数千行、数万行のデータであっても、わずか数十秒で元の綺麗な状態に復元することが可能だ。
- 外部システムからダウンロードしたCSVが読めない!Excel 文字化け 対処法の根本原因
- 標準機能「データの取得」を使ってUTF-8ファイルを確実に読み込む
- Windows標準のメモ帳を「文字コード変換器」として使い倒す
- 経理や営業の現場で致命的となる「先頭の0消失」と「文字化け」の同時回避術
- Power Queryで自動化する!二度と文字コード設定を繰り返さない仕組み作り
- 日本特有の「Shift-JIS」と世界標準の「UTF-8」がExcelで衝突する仕組み
- 海外拠点から届くEUC-JPやUTF-16形式の特殊な文字化けを見極める
- 文字化けしたまま保存してしまった!絶望的な状況からデータを救い出す最終手段
- Macユーザーとファイルをやり取りする際に発生する「濁点・半濁点」の分離問題
- システム担当者に伝えたい「現場が泣かない」CSV出力仕様の提言
- 実務の疑問を解消するFAQ:特定の記号だけが化けるのはなぜ?
- 明日からの実務に取り入れる「文字化けに振り回されない」ためのチェックリスト
外部システムからダウンロードしたCSVが読めない!Excel 文字化け 対処法の根本原因
ExcelでCSVファイルを開いた際に発生する文字化けの正体は、ファイルが作成された際の「文字コード」と、Excelが読み取ろうとする「文字コード」の不一致である。現在のWebサービスやクラウド型システム(Salesforceやkintone、各種ERPなど)の多くは、世界標準である「UTF-8」という文字コードでデータを出力する。一方で、日本のWindows環境におけるExcelは、伝統的に「Shift-JIS(CP932)」という文字コードを前提としてファイルを直接開こうとする性質がある。この「UTF-8で書かれた手紙を、Shift-JISという眼鏡で読もうとする」ズレこそが、文字化けを引き起こす最大の要因だ。
「BOM」の有無が運命を分ける
実務で非常に重要なのが「BOM(Byte Order Mark)」という概念だ。UTF-8には、ファイルの先頭に「これはUTF-8です」という識別票(BOM)が付いているものと、付いていないものの2種類が存在する。BOM付きのUTF-8であれば、最近のExcel(Microsoft 365やExcel 2019以降)はダブルクリックするだけで自動的に文字コードを判別し、正しく表示してくれることが多い。しかし、多くのシステムから出力されるCSVは「BOMなしUTF-8」であることが一般的であり、これがExcelの自動判別を狂わせる原因となっている。
初心者が陥る「二重のミス」とデータの消失リスク
筆者が社内研修で講師を務めている際、初心者が最もやりがちなミスとして挙げるのが「文字化けした状態で上書き保存してしまうこと」だ。文字化けはあくまで「表示上の解釈ミス」であるが、その状態で保存ボタンを押すと、Excelは表示されている意味不明な文字列をそのままファイルに書き込んでしまう。こうなると、元の正しい文字情報は完全に破壊され、復旧は不可能になる。文字化けに遭遇した際は、まず「何もせずに閉じる」ことが、実務における鉄則中の鉄則である。
現場で見かける「手動修正」の無謀さ
営業管理の現場などで、文字化けした数行を根性で打ち直そうとしているメンバーを見かけることがあるが、これは絶対に推奨できない。数千行のデータにおいて、どこまでが正しく表示され、どこからが化けているかを人間が判断するのは不可能に近いからだ。を学ぶ前に、まずは「正しく取り込む」技術を身につけることが、業務効率化への最短ルートと言える。

標準機能「データの取得」を使ってUTF-8ファイルを確実に読み込む
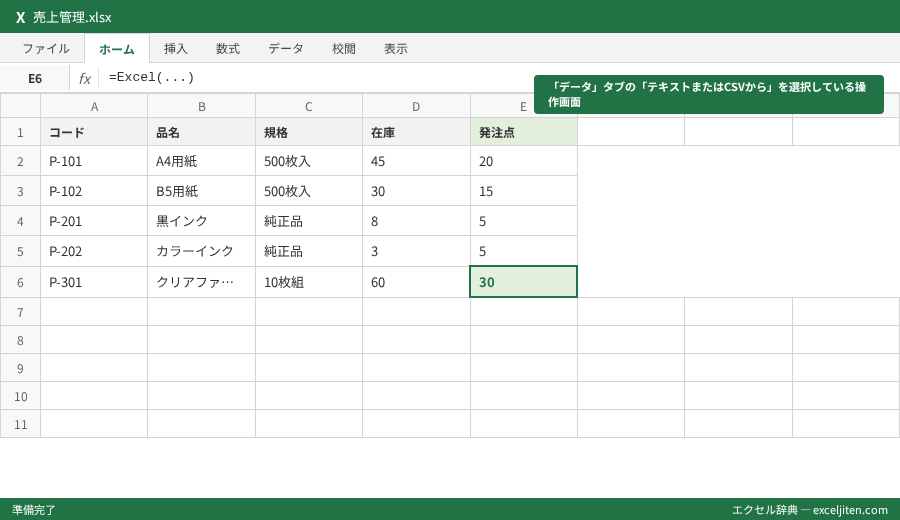
Excel 文字化け 対処法として最も確実で、かつMicrosoftも推奨しているのが、ファイルを直接開くのではなく「インポート(取り込み)」機能を利用する方法だ。特にMicrosoft 365やExcel 2016以降を使用している場合、「データ」タブにある強力なエンジンを活用することで、文字化け問題を根底から解決できる。
「テキストまたはCSVから」を選択する王道手順
以下の手順は、経理部で銀行の入出金明細を取り扱う際や、システムから出力した膨大な在庫リストを扱う際に必須となる。
1. Excelを起動し、新しい「空白のブック」を作成する。
2. 上部のリボンから「データ」タブをクリックし、左端の「データの取得と変換」グループにある「テキストまたはCSVから」を選択する。
3. 文字化けしているCSVファイルを選択し、「インポート」をクリックする。
4. プレビュー画面が表示されたら、左上の「元のファイル」というドロップダウンメニューを開く。
5. リストから「65001: Unicode (UTF-8)」を選択する。
6. プレビューの文字が正しく日本語として表示されたことを確認し、「読み込み」ボタンを押す。
プレビュー画面でチェックすべき重要項目
プレビュー画面では、文字コード以外にも確認すべきポイントがある。それは「区切り記号」だ。通常は「カンマ」が選択されているはずだが、システムによっては「タブ」や「セミコロン」で区切られている場合もある。ここでプレビューの表がガタガタになっている場合は、区切り記号を変更してみよう。筆者の経験では、海外製のマーケティングツールから出力したデータでセミコロン区切りになっているケースをよく見かける。
読み込み先の指定によるワークシートの管理
「読み込み」ボタンの横にある矢印をクリックして「読み込み先」を選択すると、データを既存のシートの特定のセルから開始したり、データモデルに追加したりすることができる。集計用のテンプレートファイルが既にある場合は、この「読み込み先」指定が非常に便利だ。
ポイント: ファイルをダブルクリックして開く癖を捨て、「データ」タブから取り込む習慣をつけるだけで、文字化けトラブルの9割は回避できる。
Windows標準のメモ帳を「文字コード変換器」として使い倒す
Excelのインポート機能が何らかの理由で使えない、あるいはもっと手軽に解決したいという場面では、Windowsに標準搭載されている「メモ帳」アプリが最強の助っ人になる。ITに詳しくない他部署のメンバーに電話越しで指示を出す際、筆者が最も重宝しているのがこのテクニックだ。
メモ帳を経由して「Excelが好きな言葉」に翻訳する
メモ帳はExcelよりも文字コードの自動判別能力が高い。この特性を利用して、ファイルの形式を変換してしまうのだ。
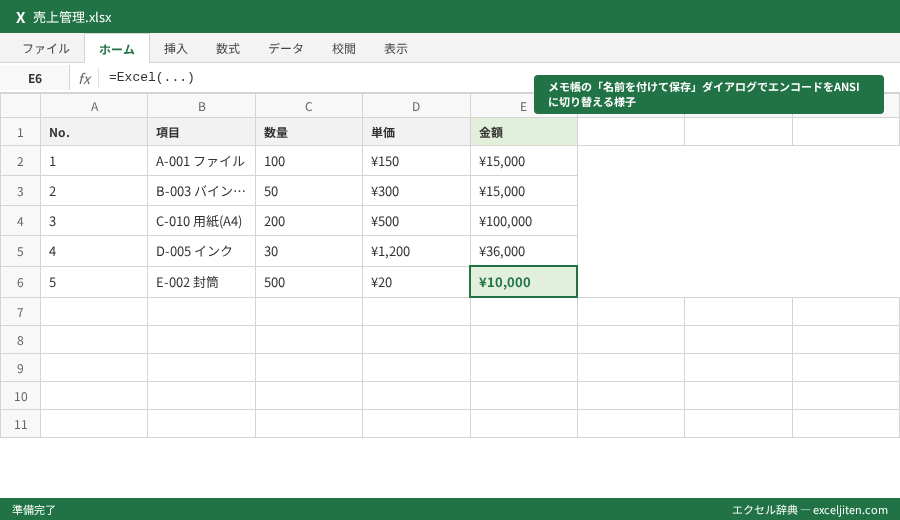
1. 文字化けしているCSVファイルを右クリックし、「プログラムから開く」から「メモ帳」を選択する。
2. メモ帳で開くと、多くの場合、文字化けせずに内容が表示される(もしここでも化けている場合は、別の文字コードの可能性がある)。
3. メモ帳のメニューから「ファイル」→「名前を付けて保存」をクリックする。
4. 保存ダイアログの下部にある「エンコード」という項目を確認する。ここが「UTF-8」になっているはずなので、これを「ANSI」に変更する。
5. ファイル名の末尾はそのまま(.csv)で、上書き保存、または別名で保存する。
6. 保存したファイルをExcelでダブルクリックして開く。
「ANSI」とは一体何なのか?
ここで指定する「ANSI」とは、Windowsの日本語環境においては「Shift-JIS(CP932)」を指す。つまり、「Excelが直接開ける形式に、メモ帳を使って翻訳してあげた」ことになる。この方法は、特にマクロ(VBA)などが組み込まれた古いファイルに対して外部データを取り込みたい時に、余計な設定を増やさずに済むため非常に重宝する。
メモ帳でも文字化けする場合の対処
万が一、メモ帳で開いても文字化けしている場合は、ファイルが「UTF-16」や「EUC-JP」といった特殊な形式である可能性が高い。その場合は、VS Codeなどの高機能なテキストエディタを使用するか、後述するPower Queryでの対応が必要になる。実務でよく見かけるのは、古いUNIX系システムから出力された勤怠データがEUC-JPになっているケースだ。
経理や営業の現場で致命的となる「先頭の0消失」と「文字化け」の同時回避術
Excel 文字化け 対処法を実践する際、もう一つセットで襲いかかってくる厄介な問題がある。それが「先頭の0(ゼロ)落ち」だ。顧客コード「00123」が、Excelで開いた瞬間に数値の「123」として扱われ、大切な「00」が消えてしまう現象である。これは経理部門の振込データ作成や、営業管理のJANコード管理において致命的なミスに繋がる。
「データの変換」で列の型を固定する
この問題を解決するには、前述した「データの取得」手順の途中で、ひと手間加える必要がある。
1. 「データの取得」→「テキストまたはCSVから」でファイルを選択。
2. プレビュー画面で「元のファイル」を「UTF-8」に設定。
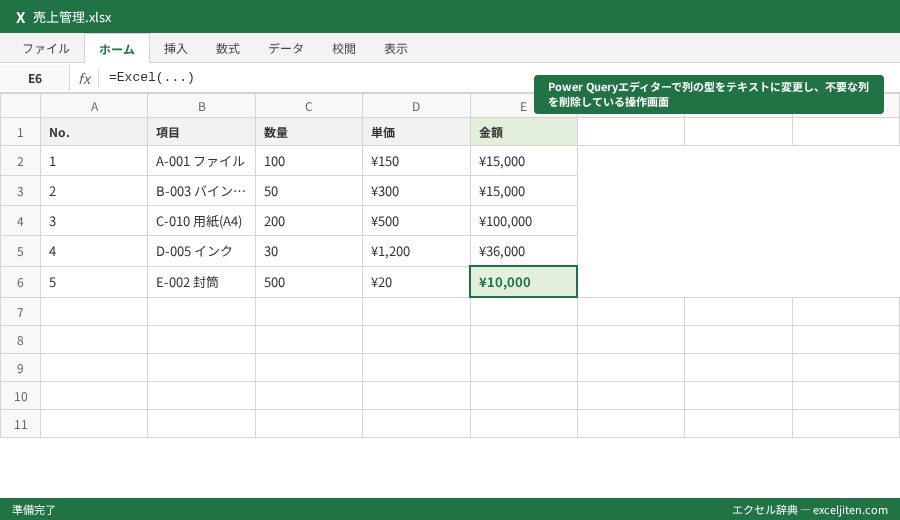
3. ここで「読み込み」をすぐ押さず、隣にある「データの変換」をクリックする。
4. Power Queryエディターが開くので、先頭の0を保持したい列の見出しをクリックする。
5. リボンの「変換」タブにある「データ型」を「数値」から「テキスト」に変更する。
6. 「型の変更を置換しますか?」というメッセージが出たら「現在のものを置換」を選択する。
7. 「00123」のように、0が表示されたことを確認して「閉じて読み込む」をクリックする。
実務事例:営業部での顧客リスト管理
筆者が過去にコンサルティングした企業では、営業担当者が名刺管理システムから出力したCSVをExcelで直接開き、顧客コードの先頭0が消えたまま顧客マスターに上書き保存してしまった。その結果、既存システムとの照合ができなくなり、復旧に3日間を要したという事例がある。この「型」の意識がないままCSVを扱うのは、まさに「爆弾を抱えて仕事をしている」ようなものだ。
郵便番号や電話番号での注意点
郵便番号「060-0001」などのハイフンがあるデータはテキストとして認識されやすいが、電話番号を「0312345678」のようにハイフンなしで出力するシステムの場合、Excelは即座に数値と判断して先頭の0を削ってしまう。を工夫するよりも、取り込み段階で「テキスト型」として定義するのが最も安全で確実な方法である。
注意点: 一度数値として確定してしまったデータに後から「00」を付けても、それは単なる表示形式の変更であり、データの実体(値)が変わっていないため、システム連携時にエラーになるリスクがある。
Power Queryで自動化する!二度と文字コード設定を繰り返さない仕組み作り
毎日、あるいは毎週同じシステムのデータを加工する実務家にとって、毎回文字コードを指定してインポートするのは時間の無駄だ。そこで活用したいのが「Power Query(パワークエリ)」である。これを使えば、「文字化け解消」と「データ整形」の手順をExcelに記憶させ、次からはワンクリックで完了させることができる。
「更新」ボタン一つで済む魔法の設定
Power Queryで一度取り込み設定を作っておけば、元のCSVファイルが更新されても、Excel側の「データ」タブにある「すべて更新」をクリックするだけで、最新のデータが文字化けせずに、かつ先頭の0も保持された状態でシートに展開される。
1. 前述の「データの変換」までの手順を行い、文字コードと型を設定する。
2. 「閉じて読み込む」でシートにデータを出力する。
3. 翌日、新しいデータが同じファイル名で保存されたら、Excelを開いて「すべて更新」を押すだけ。
実務事例:経理部での月次予算実績比較
ある製造業の経理チームでは、各支店から送られてくるUTF-8の売上データを手作業でShift-JISに変換し、VLOOKUP関数で集計表に転記していた。この作業に毎月5時間を費やしていたが、Power Queryを導入したところ、指定のフォルダにファイルを置くだけで集計が完了するようになり、作業時間は5分に短縮された。研修でこの方法を教えると、多くの受講生が「今までの苦労は何だったのか」と驚愕する。
不要な列の削除と並べ替えも同時に記憶
Power Queryの真骨頂は、文字化け解消のついでに「不要な列を消す」「日付を西暦に直す」「金額の空欄を0で埋める」といったクレンジング作業を自動化できる点にある。一度定義したステップは、Microsoft公式サイトのドキュメント(https://learn.microsoft.com/ja-jp/power-query/connectors/text-csv)にある通り、再現性が保証されるため、属人化の解消にも繋がる。
日本特有の「Shift-JIS」と世界標準の「UTF-8」がExcelで衝突する仕組み
なぜこれほどまでに「Excel 文字化け 対処法」というキーワードが検索され続けるのか。その背景には、日本のIT環境が歩んできた歴史的経緯がある。この仕組みを理解しておくと、トラブル発生時に「あ、またあのパターンか」と冷静に対処できるようになる。
Shift-JISという「ガラパゴス」な利便性
1980年代から1990年代、日本語を効率的に扱うために開発された「Shift-JIS」は、少ないデータ容量で日本語を表示できる画期的な規格だった。WindowsやExcelもこれを標準として採用したため、日本のビジネス界ではShift-JISが長らく覇権を握ってきた。今でも、日本国内の老舗銀行や基幹システムでは、この形式が現役で使われている。
UTF-8という「黒船」の到来
一方で、インターネットの普及とともに、世界中のあらゆる文字(絵文字や特殊記号含む)を一律に扱える「UTF-8」がグローバルスタンダードとなった。Googleスプレッドシートや、クラウド型Saasの多くがUTF-8を採用しているのはこのためだ。しかし、Excelは「日本のユーザーが古いファイルを開けなくなると困る」という配慮から、標準の読み込み設定をShift-JISに据え置いたままにしている。この新旧の規格の「衝突地点」が、私たちのデスクの上で発生している文字化けの正体なのだ。
なぜ「csv」という形式が選ばれるのか
CSVは「Comma Separated Values(カンマで区切られた値)」の略で、特定のソフトに依存しない極めてシンプルなテキスト形式だ。それゆえに、異なるシステム間でのデータ受け渡しに多用されるが、シンプルすぎるがゆえに「このファイルは何の文字コードで書かれているか」という情報(メタデータ)を持つことができない。この「情報の欠如」が、読み手であるExcelに推測を強いているのである。
海外拠点から届くEUC-JPやUTF-16形式の特殊な文字化けを見極める
実務がグローバル化するにつれ、単なるUTF-8 vs Shift-JIS以外の文字化けにも遭遇する機会が増えている。筆者が研修で教えていると、「UTF-8に設定しても直らない!」という悲鳴が上がることがあるが、その場合はよりマイナーな文字コードを疑う必要がある。
古いUnix系やMac系の名残「EUC-JP」
かつて大学の研究室や政府機関、Unixベースの古いシステムで標準だったのが「EUC-JP」だ。これをExcelで無理やり開くと、UTF-8の時とはまた違った、独特の記号(?が並ぶなど)が混じる文字化けが発生する。インポート時の「元のファイル」の選択肢から「20932: Japanese (EUC-JP)」を探してみよう。
データベースの生出力に多い「UTF-16」
SQL Serverなどのデータベースから直接エクスポートされたデータは、UTF-16(Unicode)という形式になっていることがある。これはUTF-8よりも一文字あたりの容量が大きい形式だ。インポート時に「1200: Unicode」を選択することで解消する。
特殊文字コードの判別表
| 発生シーン | 疑うべき文字コード | インポート時のコードページ |
| :— | :— | :— |
| クラウド、モダンなWebシステム | UTF-8 | 65001 |
| 日本の古い基幹システム、銀行 | Shift-JIS | 932 |
| Unix系システム、古い公的機関 | EUC-JP | 20932 |
| Windows内部データ、DB出力 | UTF-16 | 1200 |
実務のコツ: もし文字コードが何かわからない場合は、インポート画面の「元のファイル」で上から順に日本語が含まれるコード(20932, 50220, 50221, 51932など)をプレビューで切り替えて、文字が正常に見えるものを探すのが、実は一番早い解決策だ。
文字化けしたまま保存してしまった!絶望的な状況からデータを救い出す最終手段
前述の通り、文字化けしたままの上書き保存は致命的だが、実務では他人がやってしまったミスをリカバリーしなければならない場面もある。営業部で誰かが顧客マスターを壊してしまったという連絡を受けた時、筆者が試みる「救済の3ステップ」を紹介する。
ステップ1:Windowsの「以前のバージョン」機能を確認
共有サーバー上のファイルであれば、Windowsの標準機能である「以前のバージョンの復元」が使える可能性がある。
1. ファイルを右クリックして「プロパティ」を選択。
2. 「以前のバージョン」タブをクリック。
3. 破壊される前の日時のファイルが残っていれば「復元」ボタンを押す。
これにより、文字化け保存という「人為的ミス」をなかったことにできる。
ステップ2:シャドウコピーやクラウドの履歴機能
SharePointやOneDrive、Googleドライブ上に保存していたファイルなら、より強力な「履歴機能」がある。WEBブラウザから該当ファイルを表示し、詳細設定から「バージョン履歴」をたどれば、数時間前の健全な状態に戻すことができる。実務でクラウドストレージを使う最大のメリットは、こうした文字化け事故への耐性にある。
ステップ3:もしバックアップが一切ない場合は?
残念ながら、上書き保存され、かつバックアップもない場合は、Excel単体での復旧は不可能だ。唯一の望みは、出力元となったシステム(Salesforceなど)から、再度同じ条件でエクスポートし直すことである。筆者は研修でいつも言っている。「文字化けを直すスキルよりも、文字化けしたファイルを保存しない勇気が、実務家には必要だ」と。
Macユーザーとファイルをやり取りする際に発生する「濁点・半濁点」の分離問題
デザイン部門や企画部門に多いMacユーザーから送られてきたCSVをWindowsのExcelで開くと、文字コードは合っているはずなのに、なぜか「が」が「か゛」のように、濁点が分離して表示されることがある。これは「NFD」と「NFC」というUnicode特有の正規化形式の違いが原因だ。
Macは「合成」し、Windowsは「連結」する
難しい理屈は抜きにすれば、Macのファイルシステム(APFSなど)は、「が」という文字を「か」+「濁点」という2つのパーツに分けて保持する性質がある。これをWindowsのExcelにそのまま持ってくると、Excelがそれらを一つの文字として合成できず、バラバラに表示されてしまうのだ。これも一種の「Excel 文字化け 対処法」として知っておくべき知識だ。
解決策:Wordや正規化ツールを経由する
これを直す最も簡単な方法は、一度Wordに貼り付けることだ。
1. 文字化け(濁点分離)している箇所をコピーする。
2. Wordを開き、貼り付ける。
3. Wordは優秀なので、貼り付けた瞬間に自動で濁点を合成してくれることが多い。
4. それを再度コピーしてExcelに戻す。
実務でのトラブル:VLOOKUPが効かない!
この問題の恐ろしいところは、見た目が「が」に見えていても、Excel内部では2文字としてカウントされているため、VLOOKUP関数やCOUNTIF関数で照合した際に「不一致」と判定されてしまうことだ。を探している人で、Macユーザーとのやり取りがある場合は、まずこの濁点問題を疑ってほしい。
ポイント: 濁点が分離しているかどうかを確認するには、LEN関数を使ってみよう。「が」の文字数が「1」ではなく「2」と表示されたら、それはMac由来の濁点分離ファイルだ。
システム担当者に伝えたい「現場が泣かない」CSV出力仕様の提言
もしあなたがシステム開発の要件定義に関わる立場なら、現場の「Excel 文字化け 対処法」を不要にするための仕様を提案してほしい。筆者がコンサルティングで入る際、IT部門には必ず以下のいずれかを推奨している。
推奨1:BOM付きUTF-8での出力
CSVを出力する際、ファイルの先頭にBOM(EF BB BF)を付加するだけで、Excelをダブルクリックした際の挙動が劇的に改善する。これだけで現場の「開けません」というクレームの8割は解消する。Microsoft 365ユーザーが多い現代のビジネス環境において、最もコストパフォーマンスの良い対策だ。
推奨2:Excel(.xlsx)形式での直接出力
そもそもCSVという古い形式にこだわらず、最初からExcelの標準形式(OpenXML形式)で出力できるライブラリを使用すること。これにより、文字化けだけでなく、前述の「先頭0落ち」や「日付の型化け」もすべて解決する。
推奨3:Shift-JIS出力オプションの提供
「現場は古いExcel 2013を使っている」といった制約がある場合は、出力設定で「Shift-JIS」を選択できるようにしておく。ユーザーが自分の環境に合わせて最適な形式を選べるのが、最も親切なシステム設計である。
実務の疑問を解消するFAQ:特定の記号だけが化けるのはなぜ?
社内研修の講師をしていると、特定の文字だけがどうしても直らないという質問をよく受ける。ここでは現場で頻出する「重箱の隅」的なトラブルを解消する。
Q1: 「㈱」や「①」などの機種依存文字が化ける
これは、Shift-JIS(CP932)と、他の古い文字コード(JISなど)の規格差で起こる。取り込み時に「932: Japanese (Shift-JIS)」を正確に選んでいるか確認しよう。また、相手がMacで作成した特殊記号は、Windowsでは表示不可能な場合もある。
Q2: 住所データの「〜」や「―」が化ける
これはいわゆる「波ダッシュ問題」と呼ばれる、IT業界では有名なトラブルだ。UTF-8からShift-JISに変換する際、波線の種類が複数あるために起こる。これを完全に防ぐには、一度「データの取得」で取り込んだ後、で置換して正規化するのが実務的な解決策だ。
Q3: 特定のセルだけ「・」や「?」が表示される
それは「サロゲートペア文字」と呼ばれる、非常に珍しい漢字や、最近作られた絵文字、あるいは中国語・韓国語などが含まれているサインだ。Shift-JISではこれらを表現できないため、必ずUTF-8のまま取り込み、フォントを「游ゴシック」などのUnicode対応フォントに設定して対応しよう。
Q4: CSVファイルを編集して保存したら、次から文字化けするようになった
これは、編集後の保存時にExcelが勝手に文字コードをShift-JISに変えてしまったからだ。編集したCSVを保存する際は、「名前を付けて保存」からファイルの種類を「CSV UTF-8 (コンマ区切り)(.csv)」と明記されているものを選択する必要がある。
明日からの実務に取り入れる「文字化けに振り回されない」ためのチェックリスト
「Excel 文字化け 対処法」をマスターしたあなたが、明日から職場で迷わないための要点をまとめる。文字化けは、一度正しい知識を身につければ、恐れるに足りない些細な現象だ。
CSVをいきなりダブルクリックしない: 常に「データ」タブの「テキストまたはCSVから」を使う意識を持つ。
「元のファイル」で65001 (UTF-8) を試す: 日本語環境での文字化け原因の第一位はこれだ。
「データの変換」で先頭の0を守る: 読み込み前に「テキスト型」へ変更する一手間を惜しまない。
文字化けしたまま保存は絶対禁止: 迷ったら「保存せずに閉じる」が鉄則。
ルーチンワークならPower Queryで自動化: 二度と同じ設定を繰り返さない環境を作る。
* Macユーザーとのやり取りでは「濁点分離」を疑う: 見た目が合っていても、関数が効かないリスクを知っておく。
実務でExcelを使い倒す者にとって、データを取り込む作業は全ての始まりである。ここがスムーズにいかないと、その後の集計や分析に充てるべき貴重な時間が削られてしまう。本記事で紹介したテクニックを活用し、文字化けという「無駄な戦い」を卒業して、本来の付加価値の高い業務に専念していただきたい。

コメント