金曜日の夕方17時、急ぎで依頼された5,000件の顧客リストのクレンジング作業。不揃いな商品コードから「製造年」と「カテゴリ」を抜き出し、さらに「枝番」を分離して集計しなければならない場面を想像してください。これを1件ずつ手作業でコピー&ペーストしていれば、どれほどの時間とミスを誘発することでしょうか。
実務の現場では、基幹システムから書き出したCSVデータが、必ずしも分析しやすい形式になっているとは限りません。むしろ、複数の情報が1つのセルに詰め込まれた「複合データ」であることが一般的です。こうしたデータの山を、瞬時に使い勝手のよい情報へと整理するために不可欠なのが、テキスト操作の基本三種、LEFT RIGHT MID 関数です。
経理部門で15年、数多の決算書や管理資料を作成してきた筆者の経験から言えば、これらの関数を使いこなせるかどうかは、単なるスキルの差ではなく、業務を「定時で終わらせる力」そのものです。社内研修の講師を務める際も、私はまずこの3つの関数の徹底的な理解から始めます。なぜなら、VLOOKUPやピボットテーブルを高度に使いこなすための前処理として、文字列操作は避けて通れないからです。
今回は、単なる構文の紹介に留まらず、私が実務の最前線で直面してきたトラブルや、大手企業の営業管理部門へアドバイスしてきた「ミスを防ぐデータ設計術」を交えながら、文字列操作の真髄を紐解いていきます。
- LEFT RIGHT MID 関数 でテキストデータを自由自在に操るための基礎知識
- 売上管理表の型番から商品情報を切り分ける現場のルーティン
- 顧客リストの電話番号や住所から特定の情報を抽出する手法
- 経理業務で頻出する「8桁の数字」を日付データとして再構成する
- 固定長ではない不規則な文字列から特定の要素を抜き出す応用術
- 単なる抽出では解決できない「複雑な文字列」を整形する高度なアプローチ
- 実務で遭遇する #VALUE! エラーや「数字が取り出せない」問題の解決策
- 1,000件以上のデータを一瞬で処理するためのショートカットと自動化の仕組み
- Microsoft 365の新関数 TEXTBEFORE/TEXTAFTER との使い分け
- 研修でよく聞かれる「文字列操作」に関する5つの実務的な疑問
- 実務スキルとして定着させるための習得ステップ
LEFT RIGHT MID 関数 でテキストデータを自由自在に操るための基礎知識
Excelにおける文字列操作の基本は、セルの左から数えるか、右から数えるか、あるいは途中から抜き出すかの3パターンに集約されます。これらを実行するのが、LEFT関数、RIGHT関数、およびMID関数です。
左端から指定文字数を抜き出すLEFT関数
LEFT関数は、対象となるセルの「左端」から指定した文字数分だけを抽出します。
基本構文は =LEFT(文字列, [文字数]) です。
例えば、営業部で使われる社員番号が「2026-0015」のように「入社年-連番」の形式であれば、左から4文字を抜き出すことで入社年を特定できます。
ポイント: LEFT関数の「文字数」引数は省略可能です。省略した場合は、自動的に「1」とみなされ、左端の1文字だけが返されます。研修で教えていると、律儀に =LEFT(A1, 1) と書く方が多いですが、実務では =LEFT(A1) と短縮して記述するシーンもよく見かけます。
右端から末尾を切り出すRIGHT関数
反対に、セルの「右端」から文字を数えるのがRIGHT関数です。
構文は =RIGHT(文字列, [文字数]) となります。
郵便番号「160-0023」から下4桁だけを抜き出して集計したい場合などに多用されます。
筆者が以前、経理の現場で遭遇した事例では、銀行の振込データから末尾の「振込依頼人コード」だけを抽出して入金消込を自動化する際に、この関数が威力を発揮しました。
自由な位置から抽出するMID関数の柔軟性
最も汎用性が高いのが、MID関数です。
構文は =MID(文字列, 開始位置, 文字数) で、指定した「開始位置」から「何文字分」取り出すかを指定します。
例えば、商品コード「TYO-2026-A100」の真ん中にある「2026(製造年)」だけが欲しい場合、4文字目からスタートして4文字分を取り出す、という指示が可能です。
を活用することで、複雑な規則性を持つコード体系も容易に分解できます。
Microsoftの公式サイトでも、これらの関数は「テキスト関数の基本」として紹介されており、古くからExcelを支えてきた信頼性の高い機能です。
参照: Microsoft公式: LEFT関数
売上管理表の型番から商品情報を切り分ける現場のルーティン
営業管理の現場では、1つの型番に「カテゴリ」「製品スペック」「カラー」「生産ライン」などの情報が凝縮されていることが多々あります。これらを分解せずにそのまま集計しようとするのは、まさに苦行です。
複雑な商品マスターを階層化する手順
例えば、ある製造メーカーの売上管理表で、型番が「CPU-i7-14700K-BLA」のようにハイフンで区切られているケースを考えてみましょう。
ここで、「CPU」というカテゴリ、「i7」というシリーズ、そして「BLA(ブラック)」というカラー情報を別々の列に抽出したいとします。
筆者が社内研修でよく提示する「実務解」は、まず補助列を作成することです。
- カテゴリの抽出:
=LEFT(A2, 3) - シリーズの抽出:
=MID(A2, 5, 2) - カラーの抽出:
=RIGHT(A2, 3)
このようにデータを分解することで、「カテゴリ別の売上構成比」や「カラー別の在庫推移」をピボットテーブルで瞬時に可視化できるようになります。
実務でよく見かけるのは、この分解作業を怠り、フィルターの検索窓に「BLA」と手入力して一つずつ集計している担当者です。これでは、データ量が増えた際に対応できません。
不揃いなデータ長への対応策
しかし、実務はそれほど単純ではありません。型番の長さが「CPU-i5…」と「MONITOR-4K…」のようにバラバラな場合があります。
固定の文字数指定では対応できない場合、MID関数とFIND関数を組み合わせる「可変長抽出」が必要になります。
「初心者がつまずきやすいポイント」として、MID関数の第2引数(開始位置)を固定数値にしてしまい、データが1文字ずれただけで結果が壊れてしまう失敗をよく目にします。
実務の知恵:型番の命名規則が将来的に変わる可能性がある場合、無理にLEFTやMIDだけで解決せず、後述する「区切り位置指定」や「フラッシュフィル」との併用を検討すべきです。データの「美しさ」よりも「メンテナンス性」を優先するのが、プロの実務家としての判断です。
顧客リストの電話番号や住所から特定の情報を抽出する手法
顧客情報のクレンジングは、マーケティング精度を左右する重要なプロセスです。特に、市外局番の分離や、住所データからの都道府県の抽出は頻出のタスクと言えます。
電話番号の整形と市外局番の特定
「03-1234-5678」や「090-1234-5678」など、ハイフンの位置が決まっているデータであれば、LEFT関数で =LEFT(A2, FIND("-", A2)-1) と記述することで、市外局番の桁数に関わらず正確に抽出できます。
筆者が経験したあるプロジェクトでは、全国の顧客リストからエリア分析を行う際、この手法で抽出した市外局番と、別途用意した「市外局番マスター」をVLOOKUPで紐付け、地域別の受注傾向を算出しました。
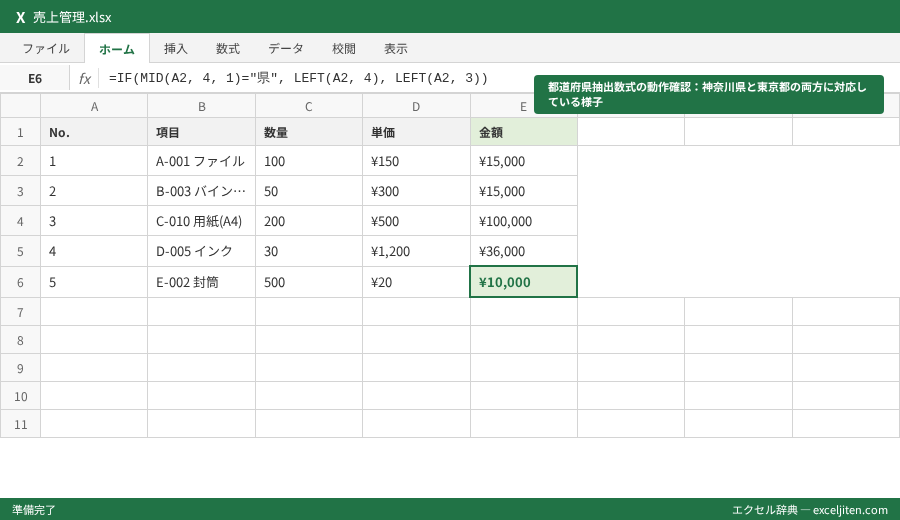
住所データから「都道府県」だけを抜き出す裏技
住所から都道府県を抜き出す際、多くの人が「左から3文字」と考えがちですが、ここで「神奈川県」「和歌山県」「鹿児島県」という4文字の壁にぶつかります。
実務で役立つ、私が研修で必ず教える数式がこちらです。
=IF(MID(A2, 4, 1)="県", LEFT(A2, 4), LEFT(A2, 3))
この数式は、「左から4文字目が『県』なら左から4文字取り出し、そうでなければ3文字取り出す」という論理です。
これにより、東京都、大阪府、京都府、北海道、そして全ての県を正しく分類できます。
「読者の失敗あるある」ですが、この条件分岐を忘れ、神奈川県を「神奈川」として抽出してしまい、その後のシステム連携でエラーを出すケースを幾度となく見てきました。
全角・半角混在問題への対処
住所や電話番号には、全角の数字やハイフンが混ざることがあります。
LEFT RIGHT MID 関数は、全角・半角を問わず「1文字」としてカウントしますが、データの比較(VLOOKUPなど)を行う際には、これらが混在していると「一致しない」とみなされます。
抽出する前に ASC関数 で半角に統一しておくのが、実務における鉄則です。
の工程を挟むことで、分析の精度は飛躍的に高まります。
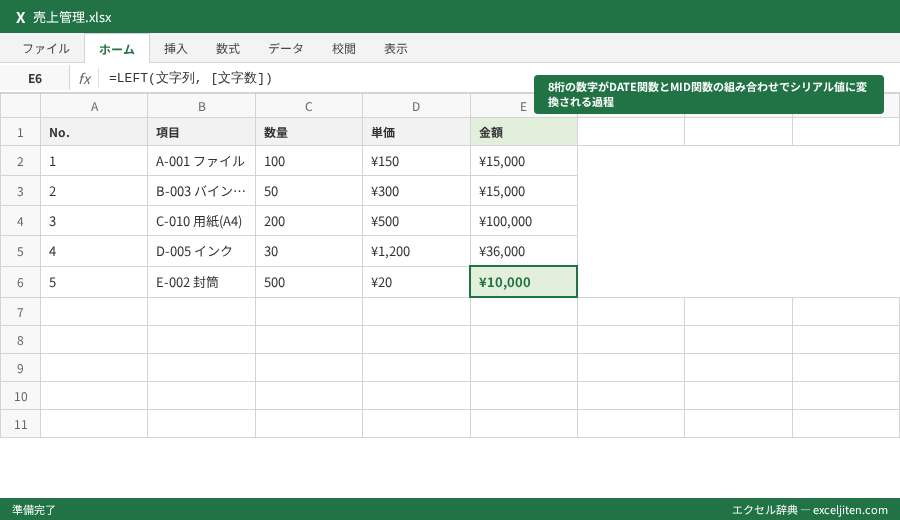
経理業務で頻出する「8桁の数字」を日付データとして再構成する
基幹システムからエクスポートしたデータが「20260513」のような「8桁の数値(または文字列)」になっていることはありませんか? これはExcel上では単なる数字として扱われ、そのままでは日付の計算や「月別集計」ができません。
MID関数で年月日に切り分けるロジック
この8桁の数字を、Excelが認識できる「シリアル値」に変換するために、MID関数を駆使します。
例えば、A2セルに「20260513」がある場合、以下のように分解します。
- 年:
MID(A2, 1, 4) - 月:
MID(A2, 5, 2) - 日:
MID(A2, 7, 2)
これらを DATE関数 の中に組み込みます。
=DATE(MID(A2,1,4), MID(A2,5,2), MID(A2,7,2))
これで、Excelは「2026/05/13」という日付として認識し、土日の判定や支払日の計算が可能になります。
TEXT関数との組み合わせで書式を整える
単に表示だけを「2026年05月13日」に変えたい場合は、TEXT関数との併用が便利です。
しかし、ここで注意が必要なのは、「値そのものを変えるのか、見かけだけを変えるのか」という視点です。
「経理の現場では、この設定を忘れて集計がずれるケースをよく見かけます」。
見かけだけを変えても、計算上は「20,260,513」という巨大な数字のままなので、日付としての加減算ができません。
注意点: MID関数で抽出した結果は、内部的には「文字列」として扱われます。DATE関数の引数にする場合はExcelが自動で数値変換してくれますが、他の計算式で使う場合は VALUE関数 を通すか、1 を掛けて数値化する癖をつけておくと、計算エラー(#VALUE!)を未然に防げます。
予算実績比較における「期」の判定
会計年度が4月始まりの場合、日付データから「どの四半期か」を判定する際にもMID関数が役立ちます。
「月」の情報だけをMIDで抜き出し、それをIF関数やCHOOSE関数に渡すことで、「第1四半期」「上期」などのラベルを自動付与できます。
予算管理資料を作成する際、この自動判定を組んでおくだけで、毎月の更新作業が数分で完了するようになります。
参照: Microsoft公式: MID関数
固定長ではない不規則な文字列から特定の要素を抜き出す応用術
実務で最も頭を悩ませるのが、文字数が一定ではない不規則なデータの扱いです。
「商品名(スペック)備考」のように、括弧の位置がまちまちのデータから中身だけを取り出したい、といった要求は絶えません。
FIND関数とのコラボレーションによる動的抽出
ここで登場するのが、特定の文字が「何文字目にあるか」を検索する FIND関数 です。
例えば、「(株)佐藤商事」と「鈴木建設(有)」が混在するリストから、会社名だけを抜き出したい場合、括弧の位置を動的に特定する必要があります。
左端から特定の文字までを抜き出す基本形は以下の通りです。
=LEFT(A2, FIND("(", A2)-1)
これにより、左から数えて「(」が出てくる直前までの文字を正確に取得できます。
筆者が以前、総務部の名簿整理を手伝った際は、この手法を使って「部署名(役職名)」というデータから部署名だけを瞬時に切り分けました。
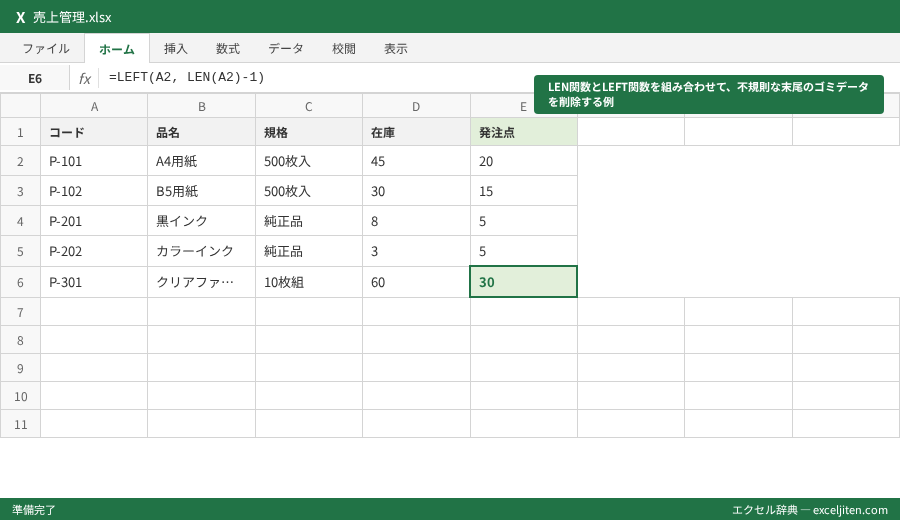
LEN関数で全体の長さを把握し末尾を調整する
RIGHT関数を使う際、末尾から「不要な固定文字数」を除きたい場合があります。
例えば、「東京都新宿区西新宿1-1-1 」のように、末尾に不規則な空白や特定の記号が含まれているケースです。
LEN関数(文字列の長さを返す)を使い、=LEFT(A2, LEN(A2)-1) とすれば、どんな長さのデータでも「最後の1文字だけを消す」という処理が可能になります。
プロのコツ:不規則なデータから特定の要素を抜き出す際、私は「まずTRIM関数で余計なスペースを消す」ことから始めます。見た目では分からない末尾のスペースが原因で、FIND関数がエラーを返したり、抽出文字数がズレたりすることが非常に多いためです。実務のデータクレンジングにおいて、TRIM関数はLEFT RIGHT MID 関数の最高の相棒です。
不規則なデリミタ(区切り文字)が複数ある場合
「東京-新宿-001」のように、同じ区切り文字が2回以上出てくる場合、2番目の「-」の位置を特定するには、FIND関数の第3引数(開始位置)を利用します。
研修で教えていると、この「第3引数」の存在を知らない方が多く、複雑な数式を組んで自爆してしまうシーンをよく目にします。
2番目のハイフン以降を抜き出すには、1番目のハイフンの位置に1を足した場所から検索を開始させるのがスマートな解決策です。
単なる抽出では解決できない「複雑な文字列」を整形する高度なアプローチ
文字列操作の要件が複雑化してくると、LEFT RIGHT MID 関数だけでは数式が長大になり、解読不能な「スパゲッティ数式」に陥ることがあります。
REPLACE関数による「置き換え」の思考
MID関数で「ここからここを抜き出す」と考えるのではなく、「不要な部分を空白に置き換えて消す」という逆転の発想が REPLACE関数 です。
構文は =REPLACE(元の文字列, 開始位置, 文字数, 置換文字列) です。
例えば、長い製品番号の「真ん中5文字だけを消したい」場合、MIDで左右を抜き出して結合するよりも、REPLACEでその5文字を “”(空文字)に置き換える方が数式はシンプルになります。
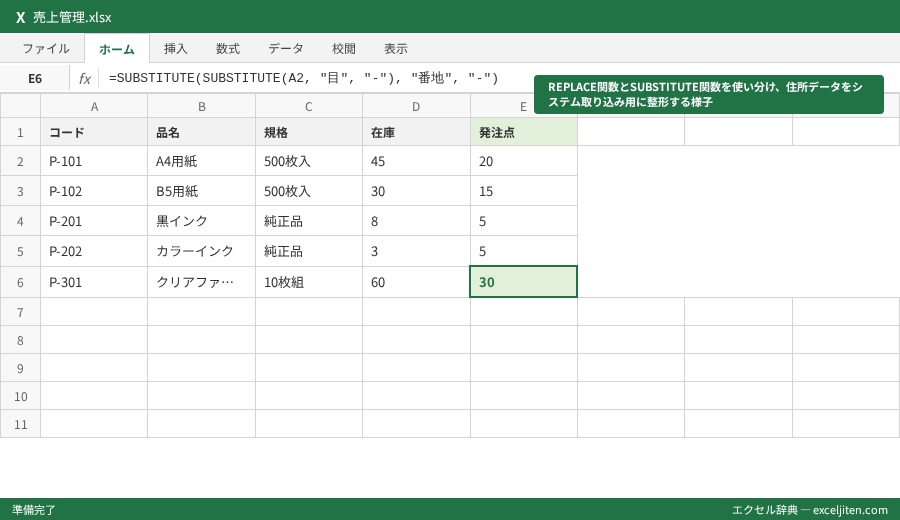
SUBSTITUTE関数で特定の単語を消去・置換する
位置ではなく「文字そのもの」を狙い撃ちするのが SUBSTITUTE関数 です。
「筆者の経験では、住所データから『丁目』や『番地』という文字をハイフンに統一する際、この関数が最も効率的でした」。
=SUBSTITUTE(SUBSTITUTE(A2, "目", "-"), "番地", "-")
このようにネスト(入れ子)にすることで、表記揺れを一気に解消できます。
抽出と結合:&演算子によるデータの再構築
抜き出したデータは、往々にして別の文字と結合して使われます。
「姓」と「名」を別々の列から抜き出し、間にスペースを挟んで「氏名」を作る。
=LEFT(A2, 2) & " " & RIGHT(A2, 2)
といった具合です。
をマスターすれば、分解したデータを再び、より管理しやすい形式へと統合できるようになります。
大手企業の経理システムへのデータインポート用ファイルを作成する際、この「分解して、加工して、再結合する」プロセスは、毎月のルーチンワークとして欠かせないものになります。
実務で遭遇する #VALUE! エラーや「数字が取り出せない」問題の解決策
「数式は合っているはずなのに、なぜかエラーが出る」「抽出した数字を足し算できない」。これらはExcel研修で最も多く寄せられる質問のツートップです。
#VALUE! エラーの正体と対策
LEFTやMID関数の引数に、負の数や文字列を指定してしまった場合にこのエラーが出ます。
特に多いのが、FIND関数との組み合わせで、検索対象の文字が見つからなかった場合です。
「FINDがエラーを出し、その結果を受け取ったLEFTが連鎖的に#VALUE!になる」という構造です。
これを防ぐには IFERROR関数 を使い、エラー時は空白を返すように設定します。
=IFERROR(LEFT(A2, FIND("-", A2)-1), A2)
ハイフンがない場合は元の値をそのまま返す、という処理を加えるだけで、シートの見た目も美しくなり、その後の集計も止まりません。
「文字列の数字」と「数値」の深い溝
LEFT RIGHT MID 関数で抜き出した数字は、見た目が数字であってもデータ型は「テキスト」です。
「実務でよく見かけるのは、抜き出した『001』という連番をSUM関数で合計しようとして、結果が0になってしまい首を傾げている担当者です」。
これを解決するには、前述の通り数値化が必要です。
一番簡単な方法は、数式の末尾に 1 を足すことです。
=MID(A2, 5, 3)*1
これにより、Excel内部でテキストから数値へと変換され、計算対象として認識されます。
注意点: ただし、商品コードのように「001」の「00」を維持したい場合は、数値化してはいけません。数値化すると「1」になってしまいます。用途に応じて、テキストのまま扱うのか、計算のために数値化するのかを明確に区別することが、データの整合性を守る鍵です。
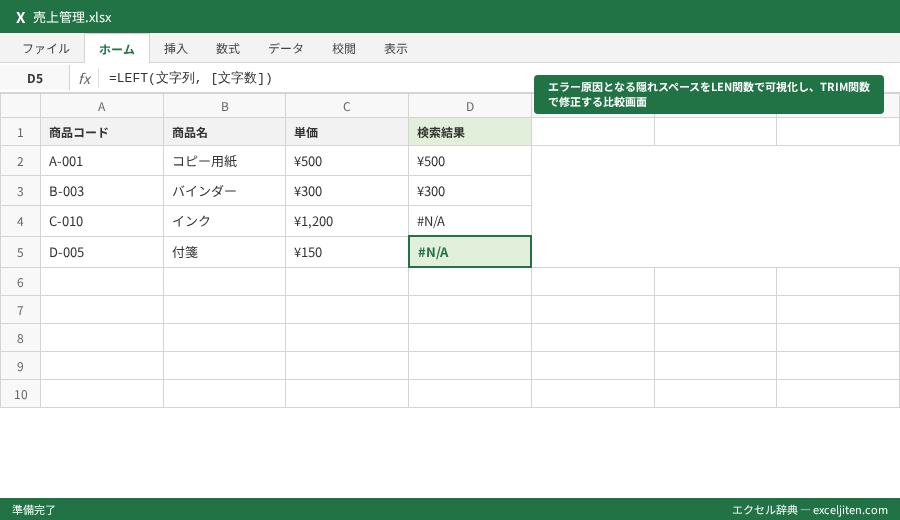
見えない「隠れスペース」の恐怖
システムの仕様上、データの末尾に「全角スペース」が隠れていることがあります。
RIGHT関数で1文字抽出したら、何も表示されない(スペースが返ってきた)というパターンです。
「実務では、まずLEN関数で文字数を数えてみて、自分の想定より1文字多ければ、高確率で末尾に何かが隠れています」。
これを一掃するには CLEAN関数 と TRIM関数 を重ね掛けします。これだけで、原因不明の抽出ミスは激減します。
1,000件以上のデータを一瞬で処理するためのショートカットと自動化の仕組み
関数を組むのは強力ですが、大量のデータを一度きり処理する場合、もっと早い方法があります。実務家として知っておくべき「時短の三段活用」を紹介します。
フラッシュフィル(Ctrl + E)の破壊的スピード
Excel 2013以降をお使いなら、まず試すべきは「フラッシュフィル」です。
A列に「東京都新宿区」、B列に「東京都」と手入力し、B3セルで Ctrl + E を押してみてください。
Excelが法則性を察知し、残りのセルにも都道府県を自動入力してくれます。
「筆者の研修では、この機能を教えた瞬間に『今までの苦労は何だったのか』と溜息が漏れることがよくあります」。
数式を組む手間すら省ける、現代Excel最強の時短テクニックです。
「区切り位置指定」で一気に列を分ける
「苗字と名前がスペースで区切られている」「CSVのカンマ区切りを直したい」という場合、LEFTやMIDを何行も書く必要はありません。
対象範囲を選択し、「データ」タブの「区切り位置」を選択。
ウィザードに従うだけで、数式を使わずに列を分割できます。
この際、分割後のデータ形式(日付として扱う、など)も指定できるため、前述の日付変換も一ステップで完了します。
Power Queryによる前処理の自動化
毎月、同じ形式の汚いデータが送られてくるなら、関数を組むよりも「Power Query」でクレンジング手順を記録すべきです。
「文字列の分割」「余白の削除」「型の変換」といったステップを一度保存すれば、次月からは「更新」ボタンを押すだけで、全てのLEFT RIGHT MID 関数的処理が自動実行されます。
中長期的な業務効率化を目指すなら、関数の先にあるこの領域へのステップアップが欠かせません。
時短テクニック:数式をコピーする際、フィルハンドルをダブルクリックしていますか? 何千行もあるデータなら、マウスでドラッグするよりもダブルクリックの方が圧倒的に速く、正確です。こうした小さな操作の積み重ねが、1日の業務時間に大きな差を生みます。
Microsoft 365の新関数 TEXTBEFORE/TEXTAFTER との使い分け
Excelは進化を続けており、最新のMicrosoft 365環境では、これまでのLEFT RIGHT MID 関数の苦労を過去のものにする新関数が登場しています。
区切り文字を基準にする革新的な関数
TEXTBEFORE関数 と TEXTAFTER関数 です。
これまでは LEFT(A2, FIND("-", A2)-1) と書いていた処理が、
=TEXTBEFORE(A2, "-")
と書くだけで済むようになりました。「ハイフンの前の文字を出す」という、人間の思考に近い記述が可能です。
同様に TEXTAFTER(A2, "-") を使えば、ハイフン以降を簡単に取得できます。
MID関数の上位互換:TEXTSPLIT
さらに強力なのが TEXTSPLIT関数 です。
1つの数式をセルに入力するだけで、区切り文字に基づいて右側のセルへ勝手にデータを展開(スピル)してくれます。
「30分かかっていた商品コードの分解作業が、この関数1つで3秒で終わるようになった事例を、最近のコンサルティング現場で目の当たりにしました」。
バージョン互換性の壁
ただし、ここでも実務的な注意点があります。
「自分が最新のMicrosoft 365を使っていても、共有相手(上司や取引先)がExcel 2019や2016を使っている場合、これらの新関数はエラー(#NAME?)になって表示されません」。
筆者が社外向けの資料を作成する際は、相手の環境が不明なことが多いため、あえて古典的で信頼性の高いLEFT RIGHT MID 関数で数式を組みます。
「どのバージョンでも動く、堅牢なシートを作る」ことも、プロの実務家としての大切な配慮です。
研修でよく聞かれる「文字列操作」に関する5つの実務的な疑問
社内研修の質疑応答コーナーで、受講生から頻繁に受ける質問とその回答をまとめました。
Q1. 数字の先頭の「0」が消えてしまうのですが?
これは、抽出した結果をExcelが勝手に「数値」と判断して、「001」を「1」に変換してしまうためです。
対策としては、抽出先のセルの表示形式をあらかじめ「文字列」にしておくか、
=TEXT(LEFT(A2, 3), "000")
のようにTEXT関数で桁数を指定して整える方法があります。顧客IDや商品コードを扱う際には、最も頻出するトラブルです。
Q2. 名字が1文字の人と2文字の人が混在する名簿はどう分ければいいですか?
名字と名前の間にスペースがあることが前提ですが、前述の FIND(" ", A2) を使ってスペースの位置を特定し、それをLEFT関数の文字数に指定するのが正解です。
名字が何文字であっても、スペースさえあれば動的に対応できます。スペースがない場合は……残念ながら手作業か、AIによる解析(Excelの最新機能など)を頼るしかありません。
Q3. 複数のセルに分かれた文字を1つにまとめるには?
「&」演算子を使うか、CONCAT関数 または TEXTJOIN関数 を使います。
特に TEXTJOIN は、間にハイフンを入れながら、空のセルは無視して結合できるため、住所のパーツを連結する際に非常に便利です。
分解(LEFT/MID/RIGHT)と結合(TEXTJOIN)は、セットで覚えるべきスキルです。
Q4. 改行が含まれるセルから、1行目だけを抜き出せますか?
可能です。セル内の改行は CHAR(10) というコードで表されます。
=LEFT(A2, FIND(CHAR(10), A2)-1)
と記述することで、改行の直前まで、つまり1行目だけを抜き出すことができます。
備考欄に書かれた長いテキストから、タイトルだけを抽出したい時に役立つテクニックです。
Q5. 住所の「番地」以降だけを消したいのですが?
番地が始まる位置に法則性(数字が始まる、など)があれば、数式で対応可能ですが、日本の住所は複雑です。
実務的な落とし所としては、まず「区切り位置指定」で数字が出るところで分けられないか試すか、フラッシュフィルで「番地なしの住所」のサンプルをいくつか提示して学習させるのが、最も打率が高い方法です。
実務スキルとして定着させるための習得ステップ
ここまで、LEFT RIGHT MID 関数の基本から応用、そしてトラブル対処法までを解説してきました。これらの関数は、一度理屈を理解してしまえば、一生モノの武器になります。
明日からの業務で、以下の3ステップを意識してみてください。
- 「不揃いなデータ」を疑う:基幹システムから出たままのデータで無理に集計しようとせず、「分解・加工」が必要な箇所を見極める。
- 補助列を恐れない:1つのセルに巨大な数式を詰め込まず、まずはLEFT用、MID用と列を分けて、計算過程を可視化する。これがミスを防ぎ、他人が見ても分かりやすいシートに繋がります。
- 関数と機能の「使い分け」を考える:一回限りの使い捨て作業なら「フラッシュフィル」、定型業務なら「関数」または「Power Query」を選択する。
「実務でよく見かけるのは、難しい関数を知っているのに、それをどう組み合わせれば業務が楽になるかのイメージが湧いていないケースです」。
本記事で紹介した事例(売上管理、顧客リスト、経理データ)は、氷山の一角に過ぎません。皆さんの手元にあるその不器用なデータも、LEFT RIGHT MID 関数というメスを入れることで、価値ある情報へと生まれ変わるはずです。
「劇的に」という言葉は使いませんが、少なくとも昨日まで1時間かかっていたコピペ作業が、今日からは数秒のドラッグで終わる。その積み重ねこそが、Excelというツールを学ぶ最大の醍醐味だと、15年の実務経験を通じて私は確信しています。
やも併せてチェックし、文字列操作の先にある「高度なデータ分析」の世界へと歩みを進めてください。データに振り回されるのではなく、データを支配する。その第一歩は、左から、右から、あるいは真ん中から、たった数文字を抜き出すことから始まるのです。


コメント